The Knuth-Morris-Pratt (KMP) algorithm revolutionized string matching by achieving linear time complexity, denoted as O(n). Introduced in 1970 by Knuth, Morris, and Pratt, this algorithm efficiently identifies patterns within text by employing a ‘Prefix Table,’ alternatively known as the LPS (Longest Proper Prefix which is also Suffix) Table. Unlike traditional methods, KMP avoids redundant comparisons, enhancing performance. By comparing characters sequentially and leveraging the preprocessed table, KMP minimizes backtracking, making it a cornerstone algorithm for efficient string pattern recognition in various computational applications.
Approaching the KMP algorithm
How does the KMP string matching algorithm work? Normally, if we didn’t have this algorithm, a very naive solution to the problem would be to use an approach similar to the sliding window approach.
Let’s take an easy example.
pattern = “def”
string = “abcdefgh”
In the complete string, we need to find a substring that is equivalent to our pattern.
The sliding window algorithm would have a window size equal to the length of the pattern. In our case, 3. We would check substrings of length 3 starting from the left (0 index) to right. It would look like this :
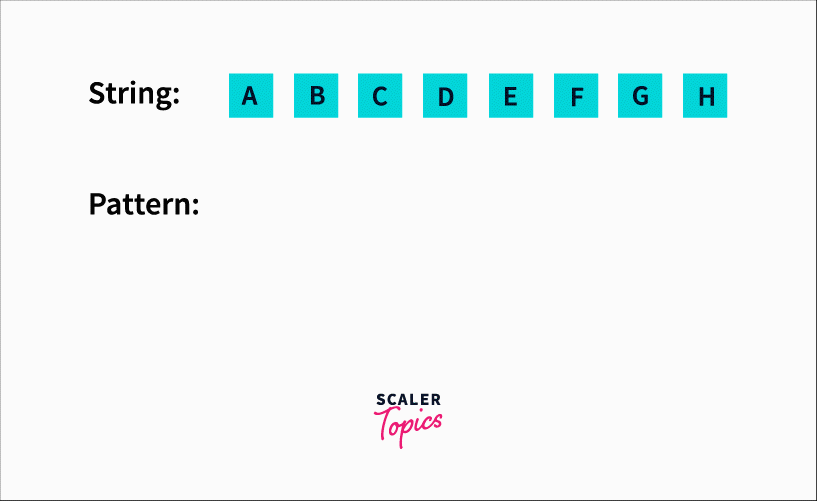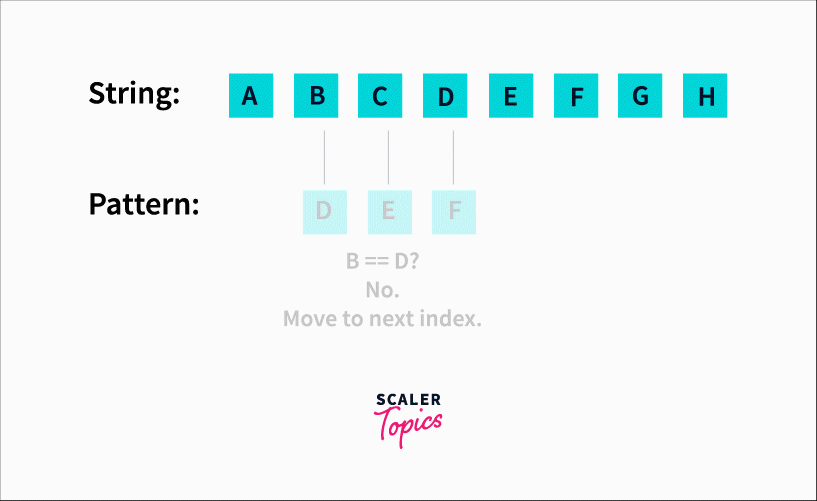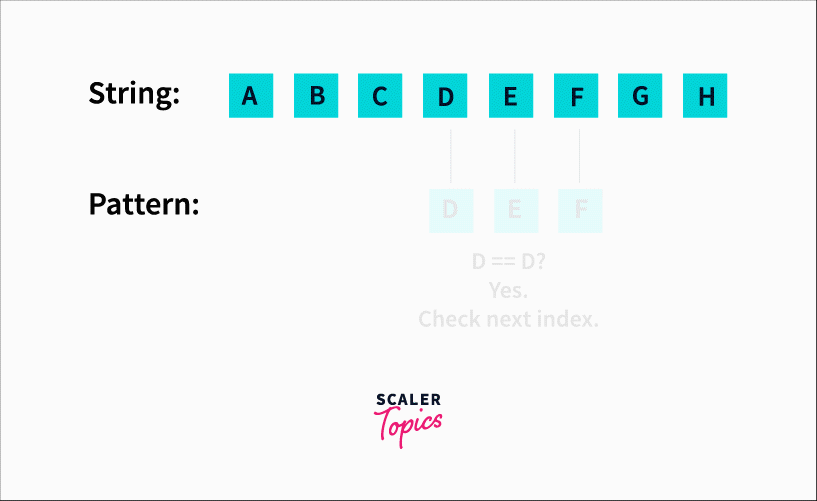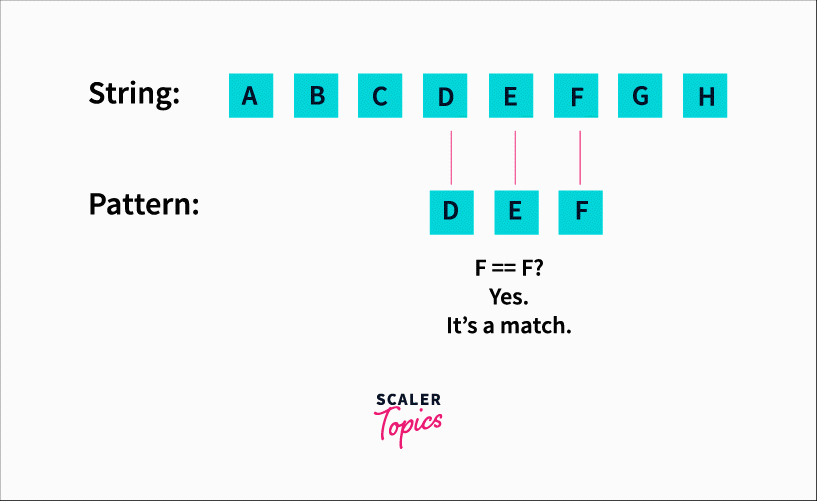
We’d be checking for each character starting from the 0th index and comparing it with ‘D’. When we find a match, we move ahead in the pattern and compare the next element with E and so on till we find a match.
This was pretty easy. Let’s look at a little more complicated example, where searching is time-consuming.
String : a b c d a b c a b c d f
Pattern : a b c d f
Let’s try using two pointers to the strings this time, as the KMP algorithm too uses 2 pointers. It’s just like we did in the previous example.
We will have an ‘i’ pointer that will move over the “string” and a ‘j’ pointer that will iterate over the “pattern”. Initially, both i and j will be on index 0.
| a | b | c | d | a | b | c | a | b | c | d | f |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| a | b | c | d | f |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 |
Now, when i = 0, and j = 0, we see that string[i] is equal to pattern[j]. Which means that there is a possibility of finding the pattern. Since there is a match, we increment both i and j.
So now i and j = 1. Again, at string[1] and pattern[1] we see that there is a match, so we increment both i and j. This goes on till index 3, i.e. when we reach the letter ‘d’, we have a match. As soon as we increment after the match, we find that at i = j = 4, there is a mismatch.
In the previous example, we did not encounter any situation where there was a half match. Whenever we wouldn’t find a match for the first element of the pattern, we would increment the index, and check for the first element of our pattern again.
We are about to do the same thing here, as in, we are going to start matching from the first index of the pattern string again. This means that j will be set to 0 once more.
| a | b | c | d | a | b | c | a | b | c | d | f |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 0 | b | c | d | f |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 |
What happens to the ‘i’ pointer? It goes back to the first index, to try and find a match. We started from the 0th index, so we just moved it by 1.
Do you see the problem here in the simple algorithm?
We are performing unnecessary computations, as in we’re repeatedly looking for a match in elements that we have already traversed, and this makes the algorithm slow.
The basic algorithm will now check for a match between j = 0, and i = 1. Pattern[j] is not equal to string[i] in this case, so we increment only the ‘i’ pointer.
| i = 1, j = 0 | mismatch |
|---|---|
| i = 2, j = 0 | mismatch |
| i = 3, j = 0 | mismatch |
Till index 4, we have mismatches. But as soon as we increment the i pointer to point to string[4], we have a match. So this time, we increment both i and j.
| i = 4, j = 0 | match |
|---|---|
| i = 5, j = 1 | match |
| i = 6, j = 2 | match |
| i = 7, j = 3 | mismatch |
As soon as we see that there is a mismatch, we need to reset the j pointer back to 0, and since we started from i = 4, we need to now move i to 5 (just incrementing by 1), and start checking for matches again. At indexes 5 and 6 we do not have a match so we just increment the i pointer by 1, but we start finding matches from index 7 onwards. This way, the algorithm moves on to find a full match starting from index 7.
Worst case :
The worst case of this algorithm is our first example.
String : c c c c c c c d
Pattern : c c c d
It will always find a pattern match up to 3 indices, but the moment it checks for ‘d’, it will not find a match and go back to the next index from where it started. This will keep on occurring till the end of the string.
Components and Terminology of KMP Algorithm
For understanding this section, let’s take an example pattern :
Pattern : a b c d a b c
Prefix :
In the KMP algorithm, we have two terms, proper prefix and suffix. A proper prefix of the pattern will be a subset of the pattern using only the beginning portion (the first index), or the first few indices of the pattern. How many characters should be in the substring prefix?
You can take as many as you want, except the last element. Why? If you take the last element of the string as well, it is the complete string, and will not be counted as a proper prefix.
Some examples of prefixes of the above pattern are :
- a
- ab
- abc
- abcd
Suffix :
A proper suffix of any pattern would be a subset of the pattern with elements taken only from the right end of the pattern as in, any number of elements, starting from the last character.
Taking the first character of the string is not allowed, as it would be the complete string and hence will not be considered as a proper suffix of the string. Some examples for the same are :
- c
- bc
- abc
- dabc
Note that there could be more than the above-mentioned prefixes and suffixes.
Let us prepare the LPS table using a few pattern examples.
Pattern 1 :
a b c d a b e a b f 1 2 3 4 5 6 7 8 9 10
Now we know that LPS[i] is the length of the longest proper prefix that is also a suffix in the first i characters, how do we calculate it? Let’s start with the leftmost character – ‘a’. We can see that the alphabet a, appears for the second time at index 4. Now, we want the longest proper prefix, so let’s also check for the next character – b. We can see that indices 5, 6 are the same as 1, 2. At the same time, indices 8 and 9 have ‘ab’ as well. The only repeating characters we can find here are ‘ab’.
So let us start preparing a table for this.
| a | b | c | d | a | b | e | a | b | f |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 |
Initially, till we do not encounter any repeating characters, we will add ‘0’ to all the characters because it is the first time they are occurring, starting from the leftmost end of the pattern.
Now, when we come to index 5, i.e. ‘a’ once more, we notice that index 1 is the same as index 5. So, we write ‘1’ for a, and ‘2’ for b since we also have a ‘b’ on index 2.
| a | b | c | d | a | b | e | a | b | f |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 2 |
We haven’t encountered an ‘e’ before, so we write 0. We see another a and b, so we write 1,2 respectively. For ‘f’ as well, we write 0.
| a | b | c | d | a | b | e | a | b | f |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 2 | 0 | 1 | 2 | 0 |
Whatever we did above, is not the algorithm or a trace of the algorithm that we will follow to create the LPS table in code, this is just how we prepare it, for understanding. You will get the same results if you trace the algorithm as well. For now, let us create a few more LPS tables to better our understanding.
Pattern 2:
a b c d e a b f a b c
1 2 3 4 5 6 7 8 9 10 11
After observing the pattern, we can see that “ab” repeats on indices 6 and 7, and “abc” repeats at the end. So our LSP table looks like this :
| a | b | c | d | e | a | b | f | a | b | c |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 1 | 2 | 3 |
Pattern 3:
a a b c a d a a b e
1 2 3 4 5 6 7 8 9 10
| a | a | b | c | a | d | a | a | b | e |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 2 | 3 | 0 |
Why have we labelled the ‘a’ on index 8 – 2? Because, if you look closely, indices 1 and 2 are both a. The same pattern repeats at 7 and 8, which is why we place 1 and 2 there.
You now know all the components there are for the KMP algorithm. We can now move forward to the complete algorithm and code.
The Knuth Morris Pratt Algorithm
How to use the LPS table?
Why did we create the LPS table? From the problem we discussed above, the partial matches were causing extra computation time.
Those partial matches can be skipped by using the LPS table, hence avoiding the unnecessary old comparisons on finding partial matches, and that is the main idea of the algorithm. We’ll see soon in the article how the LPS table will be used.
Let’s now trace the algorithm. Remember, that in the naive algorithm, the ‘i’ pointer moved backward in the string. However, here, the i pointer will not.
String :
| a | b | a | b | c | a | b | c | a | b | a | b | a | b | d |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
In the above table, we have our string and the indices of each character. As an exercise, create the LPS table of the pattern – “ababd”, and match it with the table below.
Pattern & LPS table :
| Text | a | b | a | b | d |
|---|---|---|---|---|---|
| Index | 0 | 1 | 2 | 3 | 4 |
| LPS Value | 0 | 0 | 1 | 2 | 0 |
Now, just like in our naive algorithm we created two pointers i and j, the same way here we initialize i = 0 which iterates over the string and j = 0, which will move over the LPS table. At every stage, we compare string[i] and pattern[j].
How do the iterators move?
- If there is a match, increment both i and j.
- If there is a mismatch after a match, place j at LPS[pattern[j – 1]] and compare again.
- If j = 0, and there is a mismatch, increment i.
Keeping these 3 points in mind, let’s trace the path for the above example using the KMP algorithm.
So initially i = 0, and j = 0. Now we compare string[i] with pattern[j].
| i = 0, j = 0 | Match |
|---|---|
| i = 1, j = 1 | match |
| i = 2, j = 2 | match |
| i = 3, j = 3 | match |
| i = 4, j = 4 | mismatch! |
Now at i = 4, j = 4 we have encountered a mismatch. So in this case, unlike the naive algorithm, here we do not backtrack i. For the ‘j’ pointer, we place it at LPS[j – 1] and then compare the pattern[j] with string[i].
Do you now see where our LPS table is used?
So now, we again start comparing, with i = 4, j = 0. Since we have encountered another mismatch, and j is already at 0, we need not move j, just increment the i pointer.
Again, we will compare j with i. Remember, we are comparing string[i] and pattern[j].
At i = 5, j = 0 and at i = 6, j = 1 we find a match so we increment both i and j. But when we reach i = 7, j = 2 we see that there is a mismatch. Where do you think the j pointer should move to now?
You guessed correctly, it should move to LPS[j – 1] = LPS[2 – 1] which is 0. We now compare i = 7, j = 0 and see that it is still a mismatch but since the j pointer has nowhere to go, we simply increment i.
| i = 8, j = 0 | Match |
|---|---|
| i = 9, j = 1 | match |
| i = 10, j = 2 | match |
| i = 11, j = 3 | match |
| i = 12, j = 4 | mismatch !!! |
After a series of matches, as soon as we reach i = 12, j = 4, we find a mismatch. So what do we do now? We use the LPS table and move the j pointer to LPS[j – 1] = LPS[4 – 1] = 2 and compare with string[12] again.
| i = 12, j = 2 | match |
|---|---|
| i = 13, j = 3 | match |
| i = 14, j = 4 | full match! |
We have reached the end of the pattern, i.e. j = 4 with a full match, and you have now understood the complete KMP algorithm!
Here’s a visualization for you to understand better:

Code for the KMP string matching algorithm
Here is the pseudo-code for the KMP algorithm, along with the LPS creation function. Code it in the programming language of your preference for practice.
Algorithm : KMP Match
Input : String, pattern
Output : Starting index of the match, or indication that no match was found
Let’s summarize the complete algorithm here. As discussed above in the article, in the following code for the algorithm, we first declare the LPS table and add values in it as we get them from the compute LPS function that is discussed below.
We declare two variables i and j which are the pointers iterating over the string and pattern respectively. Post that, we iterate over the string with the condition i < n, i.e. the loop runs from i = 0 till i = n (last character of the string).
Of course, as we discussed if we have a match, we will increment i and j both. However, another condition we must check here in the code is that if j pointer has reached the end of the pattern string with a match.
If that is the condition, then we know that we have found a complete match and hence the index of where the match has been found is returned.
However, if there is no match, and j is greater than 0, we move j to LPS[j – 1] and if that isn’t the case either we simply increment i. Throughout, if we aren’t able to find a match, we return -1.
LPS ← ComputeLPS(Pattern) {build LPS table function}
i ← 0
j ← 0
n ← string length
m ← pattern length
while i < n do
if pattern[j] = string[i] then {if the characters are a match}
i ← i + 1
j ← j + 1
if j = m then {j pointer has reached end of pattern}
return i - j {index of the match}
j ← LPS[j - 1]
else if i<n && pattern[j] != string[i] then {no match}
if j > 0
j ← LPS[j - 1]
else
i ← i + 1
return -1 {no match}
Algorithm : Computing LPS table function
Input : Pattern
Output : The LPS table for pattern
As we studied LPS table creation for the patterns above, let’s discuss the pseudocode. Initially, we simply create an array with size pattern length. The first element of the pattern will of course have LPS = 0.
LPS ← array [size = pattern length]
LPS[0] ← 0 {LPS value of the first element is always 0}
len ← 0 {length of previous longest proper prefix that is also a suffix}
i ← 1
m ← length of pattern
while i < m do
if pattern[i] is equal to pattern[len] then
len ← len + 1
LPS[i] ← len
i ← i + 1
else {pattern[i] is not equal to pattern[len]}
if len is not equal to 0 then
len ← LPS[len - 1]
else {if len is 0}
LPS[i] ← 0
i ← i + 1
return LPS
Complexity Analysis of KMP Algorithm
For analyzing the time complexity of the KMP string matching algorithm, let’s define a variable k that will hold the value of i – j.
k ← i – j
So, for every iteration through the while loop, we can expect one of three things to occur:
- We find a match, and hence increment both i and j, hence k remains the same
- There is a mismatch but j > 0, so i does not change and hence we can say that k increases by at least 1 since k changes from i – j to i – LPS[j – 1]
- There is a mismatch but this time j = 0, hence i is incremented and k increases by 1.
So, each iteration of the loop, either i increases by 1, or k increases by 1. Hence the greatest possible number of loops would be 2n.
Now talking about the LPS compute function, our table is computed in linear time complexity so we can say that the time complexity is O(m).
Hence, the total time complexity of our KMP algorithm is O(n + m).
Advantages of the KMP algorithm
- A very obvious advantage of the KMP algorithm is it’s time complexity. It’s very fast as compared to any other exact string matching algorithm.
- No worse case or accidental inputs exist here.
Disadvantage of the KMP algorithm
- The only disadvantage of the KMP algorithm is that it is very complex to understand.
Applications of the KMP Algorithm
It’s uses are :
- Checking for Plagiarism in documents etc
- Bioinformatics and DNA sequencing
- Digital Forensics
- Spelling checkers
- Spam filters
- Search engines, or for searching content in large databases
- Intrusion detection system
Well, it’s most common and easiest use case is checking for plagiarism. The flowchart below describes the process.
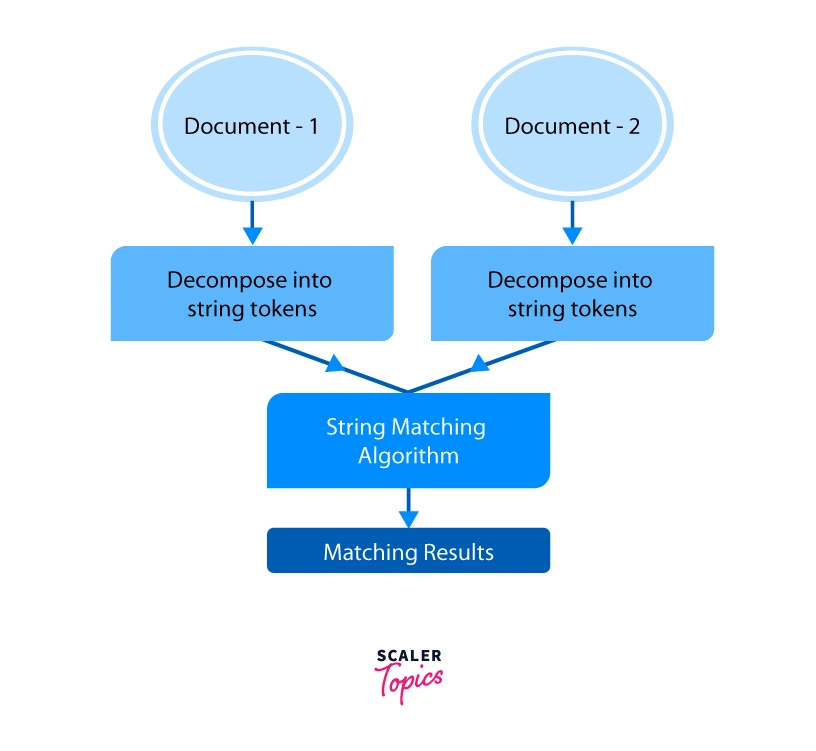
While checking for plagiarism, the documents are first decomposed into string tokens which are then matched using the string matching algorithm.
You have now mastered the KMP string matching algorithm!
Take your C++ programming skills to new heights with our Free Data Structures in C++ Certification Course. Don’t miss out!
Conclusion
- The KMP string matching algorithm can be used in various places like – plagiarism detection, digital forensics, spelling checkers etc.
- The naive string matching algorithm would either use a sliding window, or a two pointer approach which would result in extra comparisons. The time complexity for the naive algorithm would be O(mn).
- Components of the KMP algorithm:
a. Prefix.
b. Suffix.
c. LPS table : Table for detecting the Longest Proper Prefix that is also a Suffix - In this algorithm, we have 2 pointers and we work on the LPS table and the string. We compare string[i] and pattern[j]. There are 3 operations that could happen on an iteration of the while loop: a. String match, increment i and j b. String mismatch, but j > 0, so move j to LPS[j – 1] and leave i as it is and compare c. String mismatch, but j = 0, so increment i and compare
- Time complexity of the complete algorithm is O(m + n)
- The only disadvantage of the algorithm is that it is very complex to understand.