Load factor is defined as (m/n) where n is the total size of the hash table and m is the preferred number of entries that can be inserted before an increment in the size of the underlying data structure is required.
Rehashing is a technique in which the table is resized, i.e., the size of the table is doubled by creating a new table.
How hashing works?
For insertion of a key(K) – value(V) pair into a hash map, 2 steps are required:
- K is converted into a small integer (called its hash code) using a hash function.
- The hash code is used to find an index (hashCode % arrSize) and the entire linked list at that index(Separate chaining) is first searched for the presence of the K already.
- If found, it’s value is updated and if not, the K-V pair is stored as a new node in the list.
Complexity and Load Factor
- The time taken in the initial step is contingent upon both the value of K and the chosen hash function. For instance, if the key is represented by the string “abcd,” the hash function employed might be influenced by the length of the string. However, as n becomes significantly large, where n is the number of entries in the map, and the length of keys becomes negligible compared to n, the hash computation can be considered to occur in constant time, denoted as O(1).
- Moving on to the second step, it involves traversing the list of key-value pairs located at a specific index. In the worst-case scenario, all n entries might be assigned to the same index, resulting in a time complexity of O(n). Nevertheless, extensive research has been conducted to design hash functions that uniformly distribute keys in the array, mitigating the likelihood of this scenario.
- On average, with n entries and an array size denoted by b, there would be an average of n/b entries assigned to each index. This n/b ratio is referred to as the load factor, representing the burden placed on our map.
- It is crucial to maintain a low load factor to ensure that the number of entries at a given index remains minimal, thereby keeping the time complexity nearly constant at O(1).
- Complexity of Hashing
- Time complexity – O(nn)
- Space complexity – O(nn)
- Complexity of Rehashing
- Time complexity – O(nn)
- Space complexity – O(nn)
Load Factor Example
Let’s understand the load factor through an example.
If we have the initial capacity of HashTable = 16.
We insert the first element and now check if we need to increase the size of the HashTable capacity or not.
It can be determined by the formula:
Size of hashmap (m) / number of buckets (n)
In this case, the size of the hashmap is 1, and the bucket size is 16. So, 1/16=0.0625. Now compare this value with the default load factor.
0.0625<0.75
So, no need to increase the hashmap size.
We do not need to increase the size of hashmap up to 12th element, because
12/16=0.75
As soon as we insert the 13th element in the hashmap, the size of hashmap is increased because:
13/16=0.8125
Which is greater than the default hashmap size.
0.8125>0.75
Now we need to increase the hashmap size
Rehashing
As the name suggests, rehashing means hashing again. Basically, when the load factor increases to more than its pre-defined value (e.g. 0.75 as taken in the above examples), the Time Complexity for search and insert increases.
So to overcome this, the size of the array is increased(usually doubled) and all the values are hashed again and stored in the new double-sized array to maintain a low load factor and low complexity.
This means if we had Array of size 100 earlier, and once we have stored 75 elements into it(given it has Load Factor=75), then when we need to store the 76th element, we double its size to 200.
But that comes with a price:
With the new size the Hash function can change, which means all the 75 elements we had stored earlier, would now with this new hash Function yield different Index to place them, so basically we rehash all those stored elements with the new Hash Function and place them at new Indexes of newly resized bigger HashTable.
It is explained below with an example.
Why Rehashing?
Rehashing is done because whenever key-value pairs are inserted into the map, the load factor increases, which implies that the time complexity also increases as explained above. This might not give the required time complexity of O(1). Hence, rehash must be done, increasing the size of the bucketArray so as to reduce the load factor and the time complexity.
Let’s try to understand the above with an example:
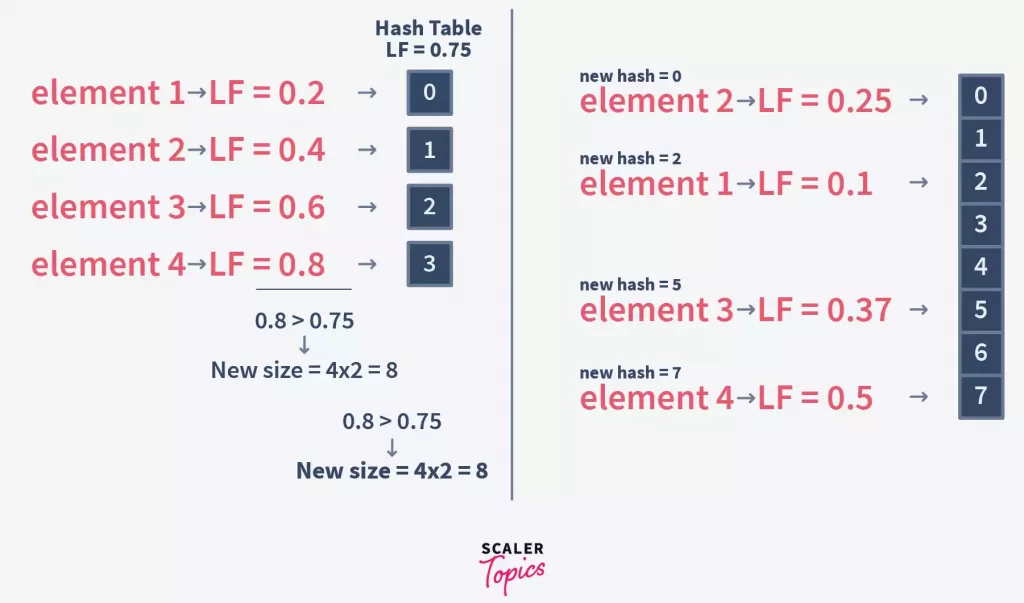
Say we had HashTable with Initial Capacity of 4.
We need to insert 4 Keys: 100, 101, 102, 103
And say the Hash function used was division method: Key % ArraySize
So Hash(100) = 1, so Element2 stored at 1st Index.
So Hash(101) = 2, so Element3 stored at 2nd Index.
So Hash(102) = 0, so Element1 stored at 3rd Index.
With the insertion of 3 elements, the load on Hash Table = ¾ = 0.74
So we can add this 4th element to this Hash table, and we need to increase its size to 6 now.
But after the size is increased, the hash of existing elements may/not still be the same.
E.g. The earlier hash function was Key%3 and now it is Key%6.
If the hash used to insert is different from the hash we would calculate now, then we can not search the Element.
E.g. 100 was inserted at Index 1, but when we need to search it back in this new Hash Table of size=6, we will calculate it’s hash = 100%6 = 4
But 100 is not on the 4th Index, but instead at the 1st Index.
So we need the rehashing technique, which rehashes all the elements already stored using the new Hash Function.
How Rehashing is Done?
Let’s try to understand this by continuing the above example.
Element1: Hash(100) = 100%6 = 4, so Element1 will be rehashed and will be stored at 5th Index in this newly resized HashTable, instead of 1st Index as on previous HashTable.
Element2: Hash(101) = 101%6 = 5, so Element2 will be rehashed and will be stored at 6th Index in this newly resized HashTable, instead of 2nd Index as on previous HashTable.
Element3: Hash(102) = 102%6 = 6, so Element3 will be rehashed and will be stored at 4th Index in this newly resized HashTable, instead of 3rd Index as on previous HashTable.
Since the Load Balance now is 3/6 = 0.5, we can still insert the 4th element now.
Element4: Hash(103) = 103%6 = 1, so Element4 will be stored at 1st Index in this newly resized HashTable.
Rehashing Steps –
- For each addition of a new entry to the map, check the current load factor.
- If it’s greater than its pre-defined value, then Rehash.
- For Rehash, make a new array of double the previous size and make it the new bucket array.
- Then traverse to each element in the old bucketArray and insert them back so as to insert it into the new larger bucket array.
However, it must be noted that if you are going to store a really large number of elements in the HashTable then it is always good to create a HashTable with sufficient capacity upfront as this is more efficient than letting it perform automatic rehashing.
Program to Implement Rehashing
The rehashing method is implemented specifically inside rehash(), where we pick the existing buckets, calculate their new hash and place them inside new indices of the newly resized array.
Java
import java.util.ArrayList;
class HashTable {
// Each bucket will have a Key and Value store, along with the pointer to the next Element, as it follows the Chaining Collision Resolution method.
static class Bucket {
Object key;
Object value;
Bucket next; // Chain
public Bucket(Object key, Object value) {
this.key = key;
this.value = value;
next = null;
}
}
// The bucket array where the nodes containing Key-Value pairs are stored
ArrayList<Bucket> buckets;
// No. of pairs stored.
int size;
// Size of the bucketArray
int initialCapacity;
// Default loadFactor
double loadFactor;
public HashTable(int initialCapacity, double loadFactor) {
this.initialCapacity = initialCapacity;
this.loadFactor = loadFactor;
buckets = new ArrayList<>(initialCapacity);
for (int i = 0; i < initialCapacity; i++) {
buckets.add(null);
}
System.out.println("HashTable created");
System.out.println("Number of pairs in the HashTable: " + size);
System.out.println("Size of HashTable: " + initialCapacity);
System.out.println("Default Load Factor : " + loadFactor + "\n");
}
private int hashFunction(Object key) {
// Using the inbuilt function from the object class
// This can return integer value for any Object.
int hashCode = key.hashCode();
// array index = hashCode % initialCapacity
return (hashCode % initialCapacity);
}
public void insert(Object key, Object value) {
// Getting the index at which it needs to be inserted
int bucketIndex = hashFunction(key);
// The first node of the chain, at that index
Bucket head = buckets.get(bucketIndex);
// First, loop through all the nodes present in the chain at that index to check if the key already exists
while (head != null) {
// If already present the value is updated
if (head.key.equals(key)) {
head.value = value;
return;
}
head = head.next;
}
// new node with the new Key and Value
Bucket newElementNode = new Bucket(key, value);
// The head node at the index
head = buckets.get(bucketIndex);
// the new node is inserted by making it the head and it's next is the previous head
newElementNode.next = head;
buckets.set(bucketIndex, newElementNode);
System.out.println("Pair(" + key + ", " + value + ") inserted successfully.\n");
// Incrementing size as new Key-Value pair is added to the HashTable
size++;
// Load factor calculated every time a new element is added.
double loadFactor = (1.0 * size) / initialCapacity;
System.out.println("Current Load factor = " + loadFactor);
// If the load factor is more than desired one, rehashing is done
if (loadFactor > this.loadFactor) {
System.out.println(loadFactor + " is greater than " + this.loadFactor);
System.out.println("Therefore Rehashing will be done.\n");
rehash();
System.out.println("New Size of HashTable: " + initialCapacity + "\n");
}
System.out.println("Number of pairs in the HashTable: " + size);
System.out.println("Size of HashTable: " + initialCapacity + "\n");
}
private void rehash() {
System.out.println("\n***Rehashing Started***\n");
// The present bucket list is made oldBucket
ArrayList<Bucket> oldBucket = buckets;
// New bucketList of double the old size is created
buckets = new ArrayList<>(2 * initialCapacity);
for (int i = 0; i < 2 * initialCapacity; i++) {
buckets.add(null);
}
// Now size is made zero and we loop through all the nodes in the original bucket list and insert it into the new list
size = 0;
initialCapacity *= 2; // New size = double of the previous size.
for (Bucket head : oldBucket) {
// head of the chain at that index
while (head != null) {
Object key = head.key;
Object val = head.value;
// calling the insert function for each node in oldBucket as the new list is now the bucketArray
insert(key, val);
head = head.next;
}
}
System.out.println("\n***Rehashing Ended***\n");
}
public void printHashTable() {
System.out.println("Current HashTable:");
// loop through all the nodes and print them
for (Bucket head : buckets) {
// head of the chain at that index
while (head != null) {
System.out.println("key = " + head.key + ", val = " + head.value);
head = head.next;
}
}
System.out.println();
}
}
public class HashTableDemo {
public static void main(String[] args) {
// Creating the HashTable
HashTable hashTable = new HashTable(5, 0.75);
// Inserting elements
hashTable.insert(1, "Element1");
hashTable.printHashTable();
hashTable.insert(2, "Element2");
hashTable.printHashTable();
hashTable.insert(3, "Element3");
hashTable.printHashTable();
hashTable.insert(4, "Element4");
hashTable.printHashTable();
hashTable.insert(5, "Element5");
hashTable.printHashTable();
}
}
C++
#include <iostream>
#include <vector>
class HashTable {
private:
// Each bucket will have a Key and Value store, along with the pointer to the next Element, as it follows the Chaining Collision Resolution method.
struct Bucket {
int key;
std::string value;
Bucket* next; // Chain
Bucket(int k, const std::string& v) : key(k), value(v), next(nullptr) {}
};
// The bucket array where the nodes containing Key-Value pairs are stored
std::vector<Bucket*> buckets;
// No. of pairs stored.
int size;
// Size of the bucketArray
int initialCapacity;
// Default loadFactor
double loadFactor;
public:
HashTable(int initialCapacity, double loadFactor) : initialCapacity(initialCapacity), loadFactor(loadFactor), size(0) {
buckets.resize(initialCapacity, nullptr);
std::cout << "HashTable created" << std::endl;
std::cout << "Number of pairs in the HashTable: " << size << std::endl;
std::cout << "Size of HashTable: " << initialCapacity << std::endl;
std::cout << "Default Load Factor : " << loadFactor << "\n" << std::endl;
}
// Hash function
int hashFunction(int key) {
return key % initialCapacity;
}
// Insert a key-value pair into the hash table
void insert(int key, const std::string& value) {
int bucketIndex = hashFunction(key);
Bucket* head = buckets[bucketIndex];
// Check if the key already exists
while (head != nullptr) {
if (head->key == key) {
head->value = value;
return;
}
head = head->next;
}
// Key not found, insert a new node
Bucket* newElementNode = new Bucket(key, value);
newElementNode->next = buckets[bucketIndex];
buckets[bucketIndex] = newElementNode;
std::cout << "Pair(" << key << ", " << value << ") inserted successfully." << std::endl;
// Increment size
size++;
// Load factor
double currentLoadFactor = static_cast<double>(size) / initialCapacity;
std::cout << "Current Load factor = " << currentLoadFactor << std::endl;
// If the load factor is more than desired one, rehashing is done
if (currentLoadFactor > loadFactor) {
std::cout << currentLoadFactor << " is greater than " << loadFactor << std::endl;
std::cout << "Therefore Rehashing will be done." << std::endl;
rehash();
std::cout << "New Size of HashTable: " << initialCapacity << "\n" << std::endl;
}
std::cout << "Number of pairs in the HashTable: " << size << std::endl;
std::cout << "Size of HashTable: " << initialCapacity << "\n" << std::endl;
}
// Rehash the hash table
void rehash() {
std::cout << "\n***Rehashing Started***\n" << std::endl;
// Make a copy of the old bucket list
std::vector<Bucket*> oldBucket = buckets;
// Create a new bucket list with double the old size
buckets.resize(2 * initialCapacity, nullptr);
// Reset size
size = 0;
// New size = double of the previous size
initialCapacity *= 2;
// Loop through all the nodes in the original bucket list and insert them into the new list
for (Bucket* head : oldBucket) {
while (head != nullptr) {
int key = head->key;
const std::string& val = head->value;
insert(key, val);
head = head->next;
}
}
std::cout << "\n***Rehashing Ended***\n" << std::endl;
}
// Print the current hash table
void printHashTable() {
std::cout << "Current HashTable:" << std::endl;
for (Bucket* head : buckets) {
while (head != nullptr) {
std::cout << "key = " << head->key << ", val = " << head->value << std::endl;
head = head->next;
}
}
std::cout << std::endl;
}
};
int main() {
// Creating the HashTable
HashTable hashTable(5, 0.75);
// Inserting elements
hashTable.insert(1, "Element1");
hashTable.printHashTable();
hashTable.insert(2, "Element2");
hashTable.printHashTable();
hashTable.insert(3, "Element3");
hashTable.printHashTable();
hashTable.insert(4, "Element4");
hashTable.printHashTable();
hashTable.insert(5, "Element5");
hashTable.printHashTable();
return 0;
}
C
#include <stdio.h>
#include <stdlib.h>
// Each bucket will have a Key and Value store, along with the pointer to the next Element, as it follows the Chaining Collision Resolution method.
struct Bucket {
int key;
char *value;
struct Bucket *next; // Chain
};
// The bucket array where the nodes containing Key-Value pairs are stored
struct HashTable {
struct Bucket **buckets;
int size;
int initialCapacity;
double loadFactor;
};
// Function to create a new Bucket node
struct Bucket *newBucket(int key, const char *value) {
struct Bucket *newNode = (struct Bucket *)malloc(sizeof(struct Bucket));
newNode->key = key;
newNode->value = strdup(value); // strdup allocates memory for a new string and copies the input string
newNode->next = NULL;
return newNode;
}
// Function to create a new HashTable
struct HashTable *newHashTable(int initialCapacity, double loadFactor) {
struct HashTable *hashTable = (struct HashTable *)malloc(sizeof(struct HashTable));
hashTable->initialCapacity = initialCapacity;
hashTable->loadFactor = loadFactor;
hashTable->size = 0;
// Allocate memory for the array of buckets
hashTable->buckets = (struct Bucket **)malloc(initialCapacity * sizeof(struct Bucket *));
for (int i = 0; i < initialCapacity; i++) {
hashTable->buckets[i] = NULL;
}
printf("HashTable created\n");
printf("Number of pairs in the HashTable: %d\n", hashTable->size);
printf("Size of HashTable: %d\n", hashTable->initialCapacity);
printf("Default Load Factor: %f\n\n", hashTable->loadFactor);
return hashTable;
}
// Hash function
int hashFunction(int key, int initialCapacity) {
return key % initialCapacity;
}
// Function to insert a key-value pair into the hash table
void insert(struct HashTable *hashTable, int key, const char *value) {
int bucketIndex = hashFunction(key, hashTable->initialCapacity);
struct Bucket *head = hashTable->buckets[bucketIndex];
// Check if the key already exists
while (head != NULL) {
if (head->key == key) {
free(head->value); // Free the old value
head->value = strdup(value);
return;
}
head = head->next;
}
// Key not found, insert a new node
struct Bucket *newElementNode = newBucket(key, value);
newElementNode->next = hashTable->buckets[bucketIndex];
hashTable->buckets[bucketIndex] = newElementNode;
printf("Pair(%d, %s) inserted successfully.\n", key, value);
// Increment size
hashTable->size++;
// Load factor
double currentLoadFactor = (double)hashTable->size / hashTable->initialCapacity;
printf("Current Load factor = %f\n", currentLoadFactor);
// If the load factor is more than desired one, rehashing is done
if (currentLoadFactor > hashTable->loadFactor) {
printf("%f is greater than %f\n", currentLoadFactor, hashTable->loadFactor);
printf("Therefore Rehashing will be done.\n");
rehash(hashTable);
printf("New Size of HashTable: %d\n\n", hashTable->initialCapacity);
}
printf("Number of pairs in the HashTable: %d\n", hashTable->size);
printf("Size of HashTable: %d\n\n", hashTable->initialCapacity);
}
// Function to rehash the hash table
void rehash(struct HashTable *hashTable) {
printf("\n***Rehashing Started***\n\n");
// Make a copy of the old bucket list
struct Bucket **oldBucket = hashTable->buckets;
// Create a new bucket list with double the old size
hashTable->buckets = (struct Bucket **)malloc(2 * hashTable->initialCapacity * sizeof(struct Bucket *));
for (int i = 0; i < 2 * hashTable->initialCapacity; i++) {
hashTable->buckets[i] = NULL;
}
// Reset size
hashTable->size = 0;
// New size = double of the previous size
hashTable->initialCapacity *= 2;
// Loop through all the nodes in the original bucket list and insert them into the new list
for (int i = 0; i < hashTable->initialCapacity / 2; i++) {
struct Bucket *head = oldBucket[i];
while (head != NULL) {
int key = head->key;
const char *val = head->value;
insert(hashTable, key, val);
head = head->next;
}
}
printf("\n***Rehashing Ended***\n\n");
}
// Function to print the current hash table
void printHashTable(struct HashTable *hashTable) {
printf("Current HashTable:\n");
for (int i = 0; i < hashTable->initialCapacity; i++) {
struct Bucket *head = hashTable->buckets[i];
while (head != NULL) {
printf("key = %d, val = %s\n", head->key, head->value);
head = head->next;
}
}
printf("\n");
}
// Function to free the memory allocated for the hash table
void freeHashTable(struct HashTable *hashTable) {
for (int i = 0; i < hashTable->initialCapacity; i++) {
struct Bucket *head = hashTable->buckets[i];
while (head != NULL) {
struct Bucket *temp = head;
head = head->next;
free(temp->value);
free(temp);
}
}
free(hashTable->buckets);
free(hashTable);
}
int main() {
// Creating the HashTable
struct HashTable *hashTable = newHashTable(5, 0.75);
// Inserting elements
insert(hashTable, 1, "Element1");
printHashTable(hashTable);
insert(hashTable, 2, "Element2");
printHashTable(hashTable);
insert(hashTable, 3, "Element3");
printHashTable(hashTable);
insert(hashTable, 4, "Element4");
printHashTable(hashTable);
insert(hashTable, 5, "Element5");
printHashTable(hashTable);
// Free the allocated memory
freeHashTable(hashTable);
return 0;
}
Python
class Bucket:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class HashTable:
def __init__(self, initial_capacity, load_factor):
self.initial_capacity = initial_capacity
self.load_factor = load_factor
self.size = 0
self.buckets = [None] * initial_capacity
print("HashTable created")
print(f"Number of pairs in the HashTable: {self.size}")
print(f"Size of HashTable: {self.initial_capacity}")
print(f"Default Load Factor: {self.load_factor}\n")
def hash_function(self, key):
return key % self.initial_capacity
def insert(self, key, value):
bucket_index = self.hash_function(key)
head = self.buckets[bucket_index]
# Check if the key already exists
while head is not None:
if head.key == key:
head.value = value
return
head = head.next
# Key not found, insert a new node
new_element_node = Bucket(key, value)
new_element_node.next = self.buckets[bucket_index]
self.buckets[bucket_index] = new_element_node
print(f"Pair({key}, {value}) inserted successfully.")
# Increment size
self.size += 1
# Load factor
current_load_factor = self.size / self.initial_capacity
print(f"Current Load factor = {current_load_factor}")
# If the load factor is more than desired one, rehashing is done
if current_load_factor > self.load_factor:
print(f"{current_load_factor} is greater than {self.load_factor}")
print("Therefore Rehashing will be done.\n")
self.rehash()
print(f"New Size of HashTable: {self.initial_capacity}\n")
print(f"Number of pairs in the HashTable: {self.size}")
print(f"Size of HashTable: {self.initial_capacity}\n")
def rehash(self):
print("\n***Rehashing Started***\n")
# Make a copy of the old bucket list
old_bucket = self.buckets[:]
# Create a new bucket list with double the old size
self.buckets = [None] * (2 * self.initial_capacity)
# Reset size
self.size = 0
# New size = double of the previous size
self.initial_capacity *= 2
# Loop through all the nodes in the original bucket list and insert them into the new list
for head in old_bucket:
while head is not None:
key = head.key
val = head.value
self.insert(key, val)
head = head.next
print("\n***Rehashing Ended***\n")
def print_hash_table(self):
print("Current HashTable:")
# Loop through all the nodes and print them
for head in self.buckets:
while head is not None:
print(f"key = {head.key}, val = {head.value}")
head = head.next
print()
# Creating the HashTable
hash_table = HashTable(5, 0.75)
# Inserting elements
hash_table.insert(1, "Element1")
hash_table.print_hash_table()
hash_table.insert(2, "Element2")
hash_table.print_hash_table()
hash_table.insert(3, "Element3")
hash_table.print_hash_table()
hash_table.insert(4, "Element4")
hash_table.print_hash_table()
hash_table.insert(5, "Element5")
hash_table.print_hash_table()
Running this with the insertion and printing of 5 Key-values will output:
HashMap created
Number of pairs in the Map: 0
Size of Map: 5
Default Load Factor : 0.75
Pair(1, Element1) inserted successfully.
Current Load factor = 0.2
Number of pairs in the Map: 1
Size of Map: 5
Current HashMap:
key = 1, val = Element1
Pair(2, Element2) inserted successfully.
Current Load factor = 0.4
Number of pairs in the Map: 2
Size of Map: 5
Current HashMap:
key = 1, val = Element1
key = 2, val = Element2
Pair(3, Element3) inserted successfully.
Current Load factor = 0.6
Number of pairs in the Map: 3
Size of Map: 5
Current HashMap:
key = 1, val = Element1
key = 2, val = Element2
key = 3, val = Element3
Pair(4, Element4) inserted successfully.
Current Load factor = 0.8
0.8 is greater than 0.75
Therefore Rehashing will be done.
***Rehashing Started***
Pair(1, Element1) inserted successfully.
Current Load factor = 0.1
Number of pairs in the Map: 1
Size of Map: 10
Pair(2, Element2) inserted successfully.
Current Load factor = 0.2
Number of pairs in the Map: 2
Size of Map: 10
Pair(3, Element3) inserted successfully.
Current Load factor = 0.3
Number of pairs in the Map: 3
Size of Map: 10
Pair(4, Element4) inserted successfully.
Current Load factor = 0.4
Number of pairs in the Map: 4
Size of Map: 10
***Rehashing Ended***
New Size of Map: 10
Number of pairs in the Map: 4
Size of Map: 10
Current HashMap:
key = 1, val = Element1
key = 2, val = Element2
key = 3, val = Element3
key = 4, val = Element4
Pair(5, Element5) inserted successfully.
Current Load factor = 0.5
Number of pairs in the Map: 5
Size of Map: 10
Current HashMap:
key = 1, val = Element1
key = 2, val = Element2
key = 3, val = Element3
key = 4, val = Element4
key = 5, val =
As we can see from the above,
Initialcapacity = 5
Load Factor = 0.75
Element1 added, LoadFactor = 0.2, and as 0.2 < 0.75, so no need to rehash.
Element2 added, LoadFactor = 0.4, and as 0.4 < 0.75, so no need to rehash.
Element3 added, LoadFactor = 0.6, and as 0.6 < 0.75, so no need to rehash.
Element4 will have LoadFactor = 0.8, and as 0.8 > 0.75, the HashTable is rehashed.
BucketSize is doubled, and all existing elements are picked and their new hash is created and placed at new Index in newly resized Hash Table.
New size = 5 * 2 = 10.
Element4 added, LoadFactor = 0.4, after rehashing.
Element5 added, LoadFactor = 0.5, and as 0.5 < 0.75, so no need to rehash.
Supercharge Your Coding Skills! Enroll Now in Scaler Academy’s DSA Course and Master Algorithmic Excellence.
Conclusion
- So we have seen the Hash Table usually guarantees Constant Time complexity of insertion and Search, given we have minimal collision in it. But since nothing comes perfect, even such a Hash Table will eventually run out of size and would need to resize it.
- This measure of when the resize must be done is governed by the Load Factor.
- But again, the resize is not just increasing the size. That’s because with the resize the Hash function used might also change.
- With the change in Hash Table, it means we now need to place the existing elements at their older indices to new indices in this newly resized Hash Table.
- So we pick all earlier stored elements, rehash them with a new hash function, and place them at a new Index.
- So both Load Factor and Rehashing come hand-in-hand ensuring the Hash Table is able to provide almost Constant Time with insertion and search operations.