The median is essentially the “halfway point” of the set of data. Order statistics are sample values placed in ascending order. The study of order statistics deals with the applications of these ordered values and their functions.
Takeaways
The distribution function for the Yi order statistic derived using the binomial distribution is
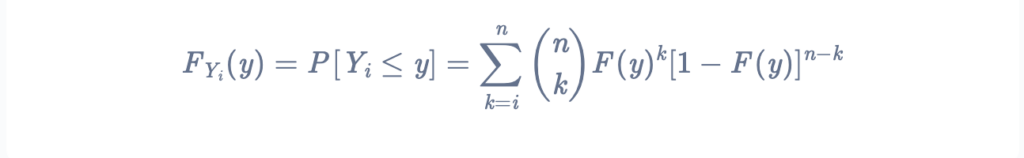
Introduction to Median and Order Statistics
On normal occasions, would you pay attention to the order, of a certain set of some random variables/numbers? Like X1, X2, … Xn? What if you did? Suppose you wanted to know the probability of the fourth largest value among the variables (X1, X2, … Xn) being less than 65 (i.e. 4th largest X < 65). Or what if you wanted to know the 90th percentile (i.e. the percentage of values that fall below 90 in the sample) of a random sample of heart rates?
Heavy terms throughout, but note that in both of these cases, what is essential is the order in which the data behaves. And that means that we would also need to know about the order of the data, and what we call the “order statistics” – Y1, Y2,Y3 … Yn.
That is exactly what we’re going to study about in this article.
What is order statistics?
Let’s take a simple example to understand “order statistics”. Here, we will take a random sample set of 5 values, of the weights of rats.
x1 = 603, x2 = 780, x3 = 710, x4 = 742, x5 = 630
What can you say about the order statistics of this set of data?
Even without knowing what order statistics are, or without knowing it’s definition, it doesn’t take rocket science to talk about the order statistics. We can probably arrange the set of data in ascending / increasing order.
So the observed order statistics are :
y1 = 603 < y2 = 630 <y3 = 710 < y4 = 742 < y5 = 780
But what happens if two rats share the same weight? Having a tie is certainly a possibility! Here, we’re going to make an assumption and rule out the possibility of this happening while studying order statistics. We will assume that the n independent observations that we are working with, come from a continuous distribution, and hence making the probability of any two observations being equal, 0.
What is a Continuous Distribution?
A continuous distribution can be defined as the plot of probabilities of the values that a continuous random variable can attain. A continuous random variable is essentially a random variable that has a set of possible values (which is called – range) that is infinite and cannot be counted.
Back to our assumption, of course in practice, ties will still be possible. But if we make the assumption that the chance of a tie occuring is near 0, we can develop the distribution theory of order statistics, which can hold even in the presence of ties, at least approximately.
We can now define a set of order statistics.
Say we have X1, X2, X3 … Xn observations belonging to a random sample that has size n, and are coming from a continuous distribution, the random variables :
Y1 < Y2 < Y3 < … <Yn
will denote the order statistics of the sample. Here,
- Y1 will be the smallest of X1, X2, X3 … Xn observations
- Y2 will be the second smallest of X1, X2, X3 … Xn observations
- Yn will be the largest of X1, X2, X3 … Xn observations
So basically, Order statistics are sample values that are placed in ascending order. These values placed in ascending order represent the “order statistics” of a sample set of data.
Note that they are to be placed specifically in ascending order to be termed as order statistics; you cannot place them in descending order.
1st Order Statistic:
Here’s a term that is used in order statistics, and that is the 1st order statistic. As the name suggests, it is literally the first in the set. The first smallest value or the first value in the order statistic – Y1 as written above is the 1st order statistic.
nth Order Statistic:
In statistics, we have another term – nth order statistic. Now of course, as we saw above, order statistics is the set arranged in ascending order, we know that the first value is going to be the smallest. The second value will be the second smallest, and the third value will be the third smallest and so on. When we say nth order statistic, we mean the nth smallest value in the order statistics.
What is Median?
Coming to the second term that we define in this article, median. What is median? The median, as you must have studied in middle school is essentially the “halfway point” of the set of data that you have, it could be anything – weights of the students in your class, or the prices of products at a store, as long as they are arranged in an increasing or decreasing order in the set.
Let’s say the size of the set (your data) is ‘n’, then if n is odd, the position of the median is
i = (n + 1) / 2
but if n is even, then we have two medians of the set of data.
i = n / 2 and i = n / 2 + 1
However, the important thing to note here is that the set must be arranged in either increasing, or decreasing order.
Minimum and Maximum Order Statistics
Now, we defined that order statistics are basically sets in ascending order. The first element in order statistics is always the smallest, and the last element is always the largest. They are arranged in ascending order.
So naturally, the minimum element will be Y1 = Ymin and the maximum element will be Yn =Ymax in a set of n random variables.
Additionally, the order statistic at a position i, Yi is called the ith order statistic.
Distribution of Order Statistics
First things first, What is a distribution function? Well, a distribution function is of course a function, an expression that tells us the probability of a system taking on a specific value, or a set of values. Generally, we describe it as the probability that any variate X, takes on a value that is either less than, or even equal to x. Say you have a set of values, of the IQ levels of different people. We want to find the probability of the IQ level of person A being less than 101.
So, in the distribution function, the value mapped to that person, would be the probability of their IQ score being less than 101. Hence, according to the definition above, the variate X = that IQ of that person, and the small x = 101, because we’re trying to find the probability of the person’s IQ being less than 101. As we mao values, we can see that the highest point in the curve would mean maximum probability, or the most common value.
A distribution function is also called a cumulative frequency function, and is sometimes denoted as F(x) or D(x).
Now, back to our ith order statistic. The distribution function of Yi (whereYi is the ith order statistic as we defined earlier) can be said to be an upper tail of a binomial distribution. Hold on, what’s the binomial distribution?
A binomial distribution is defined as the probability distribution (like we read above) but here, there are only two possible results of an experiment – success or failure. If there are just two values, how will we create a complete distribution?
For any random variable x, we describe the binomial distribution as:
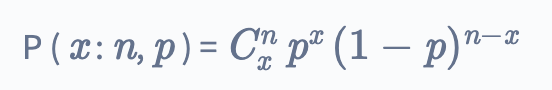
Where, n is the number of experiments, x is 0,1, 2, 3 … whole numbers (basically the x axis of the graph), p is the probability of getting success in a single experiment (like the probability is 1/2, if the experiment is tossing a coin and success is getting a head).
Like in our example of IQ’s above, we calculated the probability of a person’s IQ being less than 101, right? Here, to calculate the value that we are going to map to the x axis, we use the function above.
Now, what do we mean by upper tail? Well, the probability that the random variable at hand , YiYi, takes some values that are greater than or equal to some y is the upper tail of binomial distribution. Remember that in the definition of distribution function, we were mapping the probability of a certain value being less than some “x”? Here, we’re doing the same thing, except we want the probability of a certain value being greater than some “y” that we decide.
So, if the event where Yi ≤ y occurs then we can say that there are at least i many remaining Xj that are less than, or equal to y.
How can we say that? We established while defining order statistics that Y1 < Y2 < Y3 < … < Yi < … < Yn. So, ifYi is less than y, then there are ‘i’ many more values that are less than the value y.
If we take the event X ≤ y, and consider it as a success, and the function F(y) = P[X ≤ y] as the probability of success, then the distribution function of Y becomes :
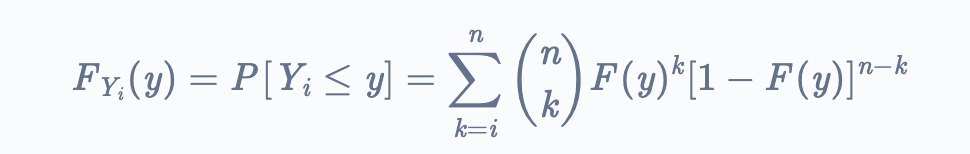
How did we come to this? Well, this is the summation of every Y encountered before Yi because we are interested in at least i many successes.
Remember the binomial distribution function above? Did you notice any similarities here? As mentioned, this is a summation of every Y value before Yi.
For a minute, let’s remove the summation and closely observe the rest of the equation. n k is the same as nCx in the binomial distribution F(y) is the probability of Yi being less than y, and is the same as ‘p’ (the probability) in the binomial distribution. Now does the formula look familiar? It’s just the same as binomial distribution! Adding the summation symbol, to add every value that we would get from the Y encountered before Yi, makes this function the distribution function of the order statistic we want. The drawing of each sample that is encountered becomes a Bernoulli trial (success or failure). You can research and read more about it on Google.
To derive the probability density function, we use the following relationship:
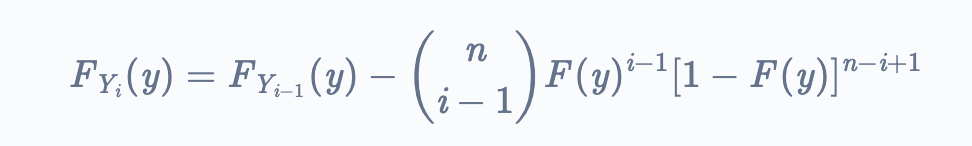
Useful functions of order statistics :
Various useful functions are given rise to with the help of order statistics. There are many functions, but the most notable ones are – sample median and sample range, which are essentially median and range of a particular sample order statistic.
Sample range :
As you must have studied, range is the difference between the largest and the smallest value given. Here is how we express it :
Range{X1,X2,…,Xn}=min{X1,X2,…,Xn}−max{X1,X2,…,Xn}=X(1)−
Sample median:
As discussed before, median is a middle value, and hence the median divides the random sample into two halves. One half contains values lesser than the median and the other half contains the values greater than the median. It is like the middle or the central order statistic.
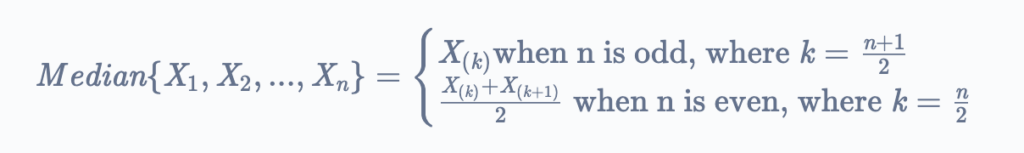
Joint Probability Density Function of Order Statistics
Generally, in life or in science, we are sometimes interested in two or more random variables at the same time. You might want to measure the height and weight of children, for example. Here, the two random variables are height and weight.
When we have situations where we would like to consider two random variables, we would have a joint distribution, which will allow us to compute the probabilities of both the variables and even understand the relationship that exists between them.
What is Joint Probability Density Function? Say you have some 2 random variables X, and Y. Then, the joint probability density distribution for the two variables is the probability distribution that gives us the probability that each of the random variables X and Y falls in any discrete set of values, or a particular defined range that are specified for that variable. Here, the variables are continuous.
For example, the random variable X could take values in a set [a, b] and the variable Y could take values in the set [c, d]. Since we are considered in both the variables together, then joined they would take on values in the product = [a, b] x [c, d]. So, the joint probability density function of X and Y written as f(x, y) will give the probability density at (x, y) in the plane {since the variables are continuous it cannot be a point in the plane, it would be represented by an integral}. The probability density at (x,y) in the plane means the probability that (X, Y) is in a small rectangle that has a width of dx and a height of dy around (x, y). It can be written as f(x, y)dx dy.
g(Y1,Y2,…,Yn)=n!f(y1)f(y2)…f(yn)
Now, we have understood the joint probability density function, but how do we calculate it for any two X and Y from our set of order statistics, or for even more?
Well, a theorem states that the joint pdf (probability density function) g(Y1 , Y2 … Yn) of an order statistics Y1< Y2< … Yn (as seen above) can be given as:

Here, n is the size of the sample, i.e. the number of elements in our order statistics, Yi represents the ith order statistics, and f(yi) represents the density function of the ith order statistics.
(Recap: We read a few paragraphs above that density function is essentially a probability function which is represented for the density of the continuous random variable, which is Yi here, lying between a certain range of values)
Conclusion
- Order statistic is a random sample that is ordered.
- The first value in the order statistic is the smallest among the random samples
- The last value in the order statistic is the largest among the random samples
- Median is the middle value of an ordered set.
- If there are even number of random values, then the two values at positions n/2 and n/2 + 1, are the medians
- If there are odd number of random values then the median lies at position (n + 1) / 2
- Two most notable useful functions of order statistics are – sample range and sample median.