Onion routing is a method of communicating anonymously over a network. A data message is contained within several layers of encryption, in an onion network. This data is transferred via a sequence of network nodes known as onion routers—the onion routers "peel" away one layer, revealing the next destination of the data.
Once the decryption of the final layer has been completed, the message arrives at its actual destination. The sender stays anonymous since every intermediary knows only the location of the immediate-adjacent nodes. While we obtain a high degree of anonymity and safety from it, specific techniques exist for bypassing onion routing.
What is Onion Routing?
Many good practices and precautionary steps exist that make web surfing secure and safer for us. Suppose you wish to send an H.T.T.P.S. (Hyper Text Transfer Protocol Secure) request to some server and somebody intercepts that request. There’s no way that person can figure out the message data as it is encrypted.
But assume that you are still not contended with this degree of safety and thus wish to increase it further. You want nobody to be able to even as much as know which server you are communicating with, if you’re firing any requests, etc. This is where you must rope in onion routing – a program that contains research that design, investigate, build, and analyze anonymous communication networks.
The emphasis here is on real practical solutions for Internet-based low-latency connections that can hold out against eavesdropping, traffic analysis, and any other attacks from internal entities such as hackers as well as external entities such as Internet routers. Onion Routing abstracts out the communicating parties from the transport medium. Thus, the only information that can be taken from the network is that communication is being made. Moreover, till the time transmission leaves the onion routing network, the contents of the communication stay hidden from eavesdroppers.
History
Onion routing was invented at the U.S. Naval Research Laboratory by employees David Goldschlag, Michael G. Reed, and Paul Syverson in the mid 1990s. The aim of developing onion routing was to secure online U.S. intelligence communications. Its further development was done by the D.A.R.P.A. (Defense Advanced Research Projects Agency). In 1998, the Navy patented it.
The same year, the very same employees made the technique public by publishing an article in the I.E.E.E. (Institute of Electrical and Electronics Engineers) journal of Communications. The article described the usage of the technique to secure a user from external agents that conduct traffic analysis attacks, eavesdropping, etc, as well as from the network itself.
The most significant portion of this research ever has been the applications and configurations of the onion routing method on currently existing digital and electronic services such as electronic cash, V.P.N. (Virtual Private Network), Email, web surfing, remote login, etc.
Based on the current technology of onion routing, in 2002, computer scientists Nick Mathewson and Roger Dingledine joined Paul Syverson, aimed at developing what as of today is the biggest and best implementation of onion routing, known as T.O.R. (The Onion Routing) project.
After the release of the code for Tor under a free license by the Naval Research Laboratory and having gained the required financial aid from a bunch of other organizations including the E.F.F. (Electronic Frontier Foundation), seven people including Mathewson and Dingledine founded The Tor Project in 2006 as a non-profit organization.
How Does Onion Routing Work?
Normally, while browsing the internet on a common web browser such as Chrome, Firefox, Edge, Safari, Opera, etc you make simple HTTP/HTTPS requests to web servers without any intermediary. There’s a simple and single connection between the server and the client, i.e. you. This way any agent on your network can know which server you’re communicating with. Well, this is not the case in onion routing!
In onion routing, the connection is maintained among many nodes. The connection keeps jumping from one server to the other. Once the connection does reach the final server on this circuit, it will be the server that we intended to connect to, and our request will be processed and a response shall be brought to us (such as the desired webpage, etc) utilizing the same network of nodes.
Now, you might be wondering why we refer to the intermediary nodes as “onion” routers. It is so because the message you transmit as well as the response you receive are both encrypted with distinct keys. Do note that the encryption keys for every hop or server visit are unique. The client can access all the keys, however, the server can access only the encryption keys that are specific to that server alone. As this whole procedure wraps a message under many encryption layers, which have to be later peeled off (just like an onion) one at a time, at every different hop, hence the names onion router and onion routing.
The Concept of Onion Routing with Example
Let us try to understand the structure and functioning of onion routing by meditating upon a fine example. Suppose you’re in China and wish to use a website that is blocked in China (say, YouTube) somehow, but at the same time not get caught by the Chinese government. Therefore, you decide to use a web browser that allows you to use the onion routers, such as TOR while browsing the internet. To be able to load YouTube webpages, your computer usually communicates with a certain server.
But now it does not do that directly. To prevent anybody from tracking your computer’s conversation with that server, TOR establishes a connection involving some intermediary routers, servers, or nodes before communicating with the actually intended server. These nodes are maintained across the globe by volunteers. A TOR network may have even hundreds of intermediary nodes in between, let us assume the number to be 3 for simplicity in this example of ours.
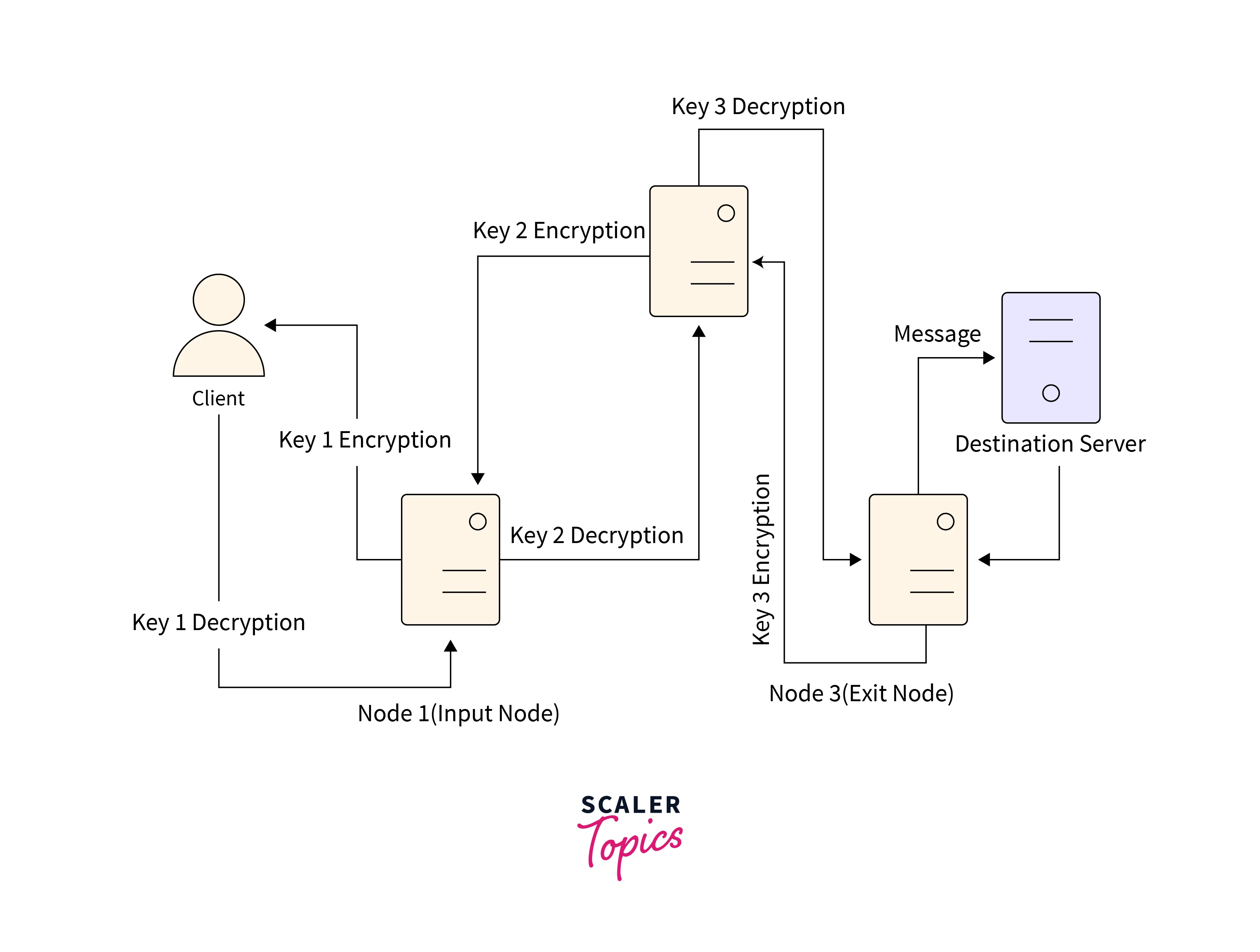
- The client message gets encrypted thrice, thus encapsulating it within three layers analogous to an onion. The client will have access to all the
3keys. - The encrypted message is then sent to the first onion node, the Input node.
- The first node stores only the second node’s address and key
1. It attempts to use key1to decrypt the message but fails to do so because there still exist two more encryption layers. Hence it transmits the message to the second node. - The addresses of the output and input nodes and key
2are present in the second node. The second node attempts to decrypt the message by using key2but fails to do so. It then transmits the message to the output node. - An HTTP request for YouTube U.R.L. (Uniform Resource Locator) is discovered by the third node (the output node). The output node decrypts the message and directs it to the final intended server.
- The required webpage is returned as a consequence of the server working upon the request.
- The response traverses backward the same path of nodes, each of which puts its cover of encryption to the message.
- Eventually, the response is brought to the client as a three-layer encrypted message. Since the client has all three keys it decrypts the message and obtains the actual response.
How Does It Provide Anonymity?
If there exists an external agent observing the first connection (client–input router). The agent can figure out only two things – the address of the input server, and the triple-encrypted message which is futile. Similarly, if the agent aims for the output node, all that can be observed is a node communicating with another. However, the attacker won’t be able to track the source of the request generated or the client. Now a question may arise, “what if the attacker is targeting the second node, will they not get to know the address of the output and the input nodes, and be able to track the destination node and the client?”.
Theoretically, yes it’s possible. But in a more practical and realistic approach, it’s not as easy as it may look. The reason is that at these nodes there are hundreds of parallel connections. Determining the exact connection that will lead to the correct client and destination is an ordeal. In our network, the second node is the middle node. However, it may simultaneously be a part of many other different such networks. In different circuits, it may be present at different positions such as input, output, intermediary, etc.
Vulnerability in Onion Routing
The one and the only issue in onion routing is that if someone happens to be observing a server in real-time and compares a response at the destination to the request made by its corresponding client by studying factors such as length, frequency of characters, etc of the intercepted request or response, and uses it to match with the same request made by a client a split-second (timestamping requests and responses help in this process), and then tracing them and knowing their activity online and crippling the concept of anonymity. Though it is possible, difficult to do. It’s virtually impossible to fix this flaw in onion routing.
Onion Routing vs VPNs
VPN is a centralized service, meaning that a central authority manages and controls the connections – the VPN provider, a private organization. The VPN provider may own and operate several servers across the globe for its customers to connect to. Although a VPN provides fast connectivity and decent privacy, trust is a prerequisite for the user, which does not translate to a solid transparent promise.
On the other hand, TOR is decentralized, owned, and managed by none. The nodes are operated by many volunteers from all over the planet. When one connects to TOR, one’s connection is routed randomly via a series of these nodes. The sequence picked and followed is random and therefore different each time a connection needs to be made. It’s a possibility, that the output node could parse unencrypted traffic that passes through it, but it won’t be able to determine the origin.
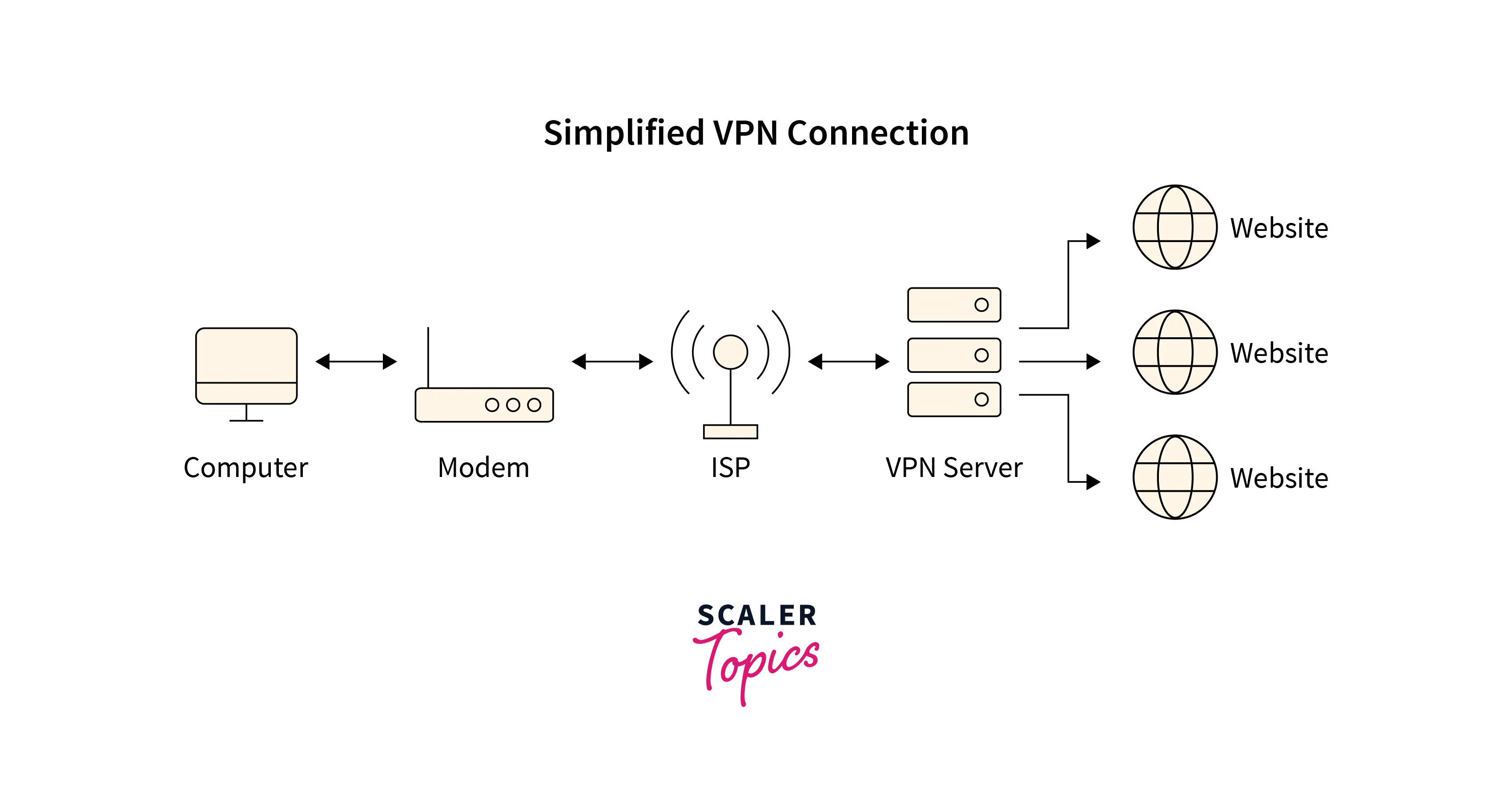
Most VPNs use only one proxy server. The outgoing data is encrypted on the sender’s device, transmitted to the VPN server, decrypted, and then sent to the actually intended destination server.
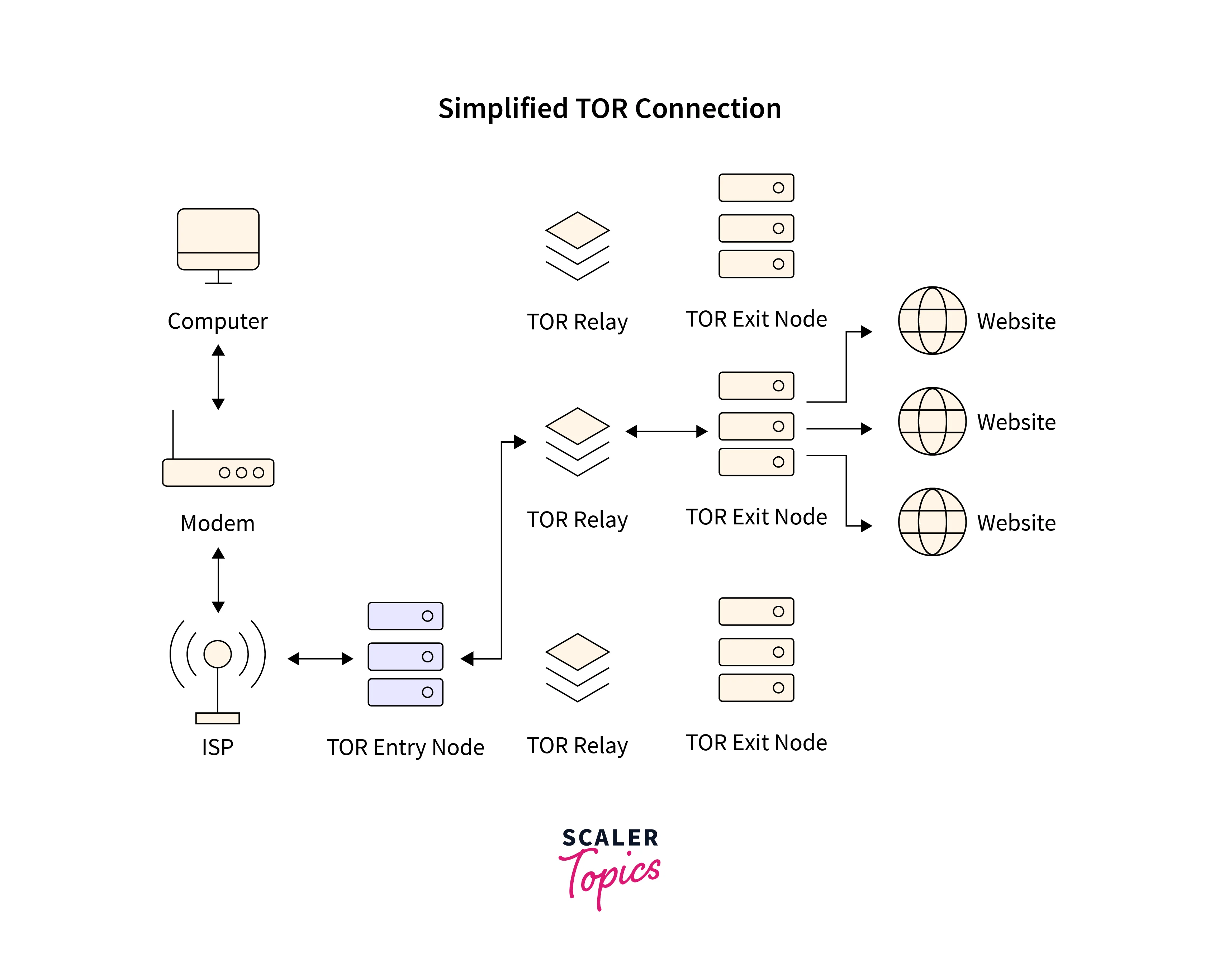
TOR transfers data through a minimum of three nodes. The sequence of nodes is random. Data and the IP (Internet Protocol) address of the next node in the series are encrypted at every node. One encryption layer is removed at each node, thus exposing the next node in the series, while keeping it hidden from all the previous nodes in the sequence. No node can check the destination, source, contents, etc of the passing internet traffic, hence making it very hard to track.
Onion Routing Clients
The Tor Project has officially developed, maintains, and distributes a web browser named the Tor Browser. It is based on the free open-source code of Mozilla’s Firefox and is itself a free and open-source application. The Tor Browser retains most of the privacy attributes of Firefox and also comes with a built-in Tor client that launches by default, each time one opens the app.
It is popular not only for just being used not only by common privacy-caring people but also by whistleblowers scared of extreme repercussions as a result of their revelations, political activists resisting repressive regimes and aggression, journalists dealing with sensitive matters, etc.
Conclusion
- Onion routing is a method of communicating anonymously over a network.
- While we obtain a high degree of anonymity and safety from it, specific techniques exist for bypassing onion routing, such as man-in-the-middle attacks, etc.
- Onion routing was invented at the U.S. Naval Research Laboratory by employees David Goldschlag, Michael G. Reed, and Paul Syverson in the mid-1990s.
- Seven people including Mathewson and Dingledine founded The Tor Project in
2006as a non-profit organization. - In onion routing, the connection is maintained among many nodes. The connection keeps jumping from one server to the other.
- TOR is decentralized, owned, and managed by none. The nodes are operated by many volunteers from all over the planet.
- TOR transfers data through a minimum of three nodes. The sequence of nodes is random.
- The Tor Project has officially developed, maintains, and distributes a web browser named the Tor Browser. It is based on the free open-source code of Mozilla’s Firefox and is itself a free and open-source application.